
A Comparison of Generative Chatbots to Hudson Labs (formerly Bedrock AI)

Generative artificial intelligence is exceptional at imitating human language patterns. Generative AI, however, is not a search engine or database that can be queried.
Some of the limitations of generative AI:
Generative models hallucinate—This means they make up very plausible-sounding false information.
A lack of reliability/repeatability—If you wish to guarantee that you get the same results every time, quality has to be sacrificed.
Reasoning errors - While language models often appear to reason like a human, they are in fact doing advanced pattern matching which can fail in unpredictable ways.
See full post here - www.hudson-labs.com/post/a-comparison-of-generative-chatbots-to-bedrock-ai
Generative models are even more likely to hallucinate (invent “facts”) in areas where there is limited existing information on the web. Finance is a blindspot for most generalist language models i.e. models like GPT-4 that have been trained primary on web data.
Generative models predict the next word to output by determining what the most likely response would be, given your input and the words it has written so far. This process ensures grammatical cohesion and that the response almost always sounds right. However, this means that generative models are not designed to provide factual information, especially in the context of a chatbot.
Chatbots do often provide factual information because it is also the “most likely” response, but it is not what they were designed to do. As shown in our experiment below, factuality rates decrease sharply in the context of more niche or complex topics like finance.
At Bedrock AI, we approach these limitations by using the right language model for the right job. We ensure factuality by making sure we never put the model in a position where it will fail. This is one of the reasons we do not provide a general purpose chatbot interface.
We use generative models to do what they do best—wordsmithing. We use in-house finance-specific models for information retrieval, topic tagging, noise reduction and more. We control the process from beginning-to-end, in order to ensure accurate, reliable results.
Our in-house language models are trained more than 8 million pages of financial disclosure for better domain understanding. Some of our summarization workflows involve six different language models designed to perform specific tasks. Learn more about our approach to language modelling and AI research here - Financial NLP and Large Language Models - The Bedrock AI Advantage.
Our experiment
To illustrate the difference between Bedrock and other generative AI tools, we tested it against two chatbots—ChatGPT and a finance-specific bot, Hila.ai — on a randomly selected group of U.S. public companies:
Dominos (DPZ),
Euronet Worldwide (EEFT),
Hamilton Lane (HLNE),
Flowers Foods (FLO), and
Extra Space Storage (EXR).
We chose midsize companies that are moderately well-known to better illustrate chatbot failure modes. Chatbots are more likely to provide correct answers for companies like Alphabet, Meta and Tesla where there is extensive information on the web.
We selected three different aspects of qualitative business analysis to test each modelling platform — their understanding and retrieval accuracy on general business operations, business segments, and seasonality. Each requires some degree of financial or corporate “knowledge”. The results are below. We think you’ll be surprised.
Note that Hila.ai is a generative chatbot designed to pull info from SEC filings and earnings transcripts, specifically. Unlike ChatGPT, each question asked to Hila requires that the user specify a filing where the bot will search for the answer. While this adds complexity to the information search process, it is set up that way to limit the opportunity for hallucination. As shown below, however, hallucination persists.
Our comparison to ChatGPT is not apples-to-apples. For the purposes of this test, we did not provide the relevant filing to ChatGPT within the prompt. We structured it this way because the majority of users we speak with interact with chatbots without providing a source file. The comparison to Hila.ai (which we believe is using the GPT-4 API) is, however, a more appropriate comparison.
The comparison to Hila.ai demonstrates our superior results when compared to a generative model-based application using best practices regarding retrieval etc., while the comparison to ChatGPT demonstrates our results compared to the most common usage pattern.
Explore our results below.
Seasonality
We asked about how seasonality affects business revenues. We chose seasonality for this assessment because it is a data point that a human with basic financial acumen can easily find. It is consistently made available in securities filings and is less complex compared to many aspects of finance. The table below summarizes the results for each tool and illustrates how severely chatbots fail when faced with lesser known topics, even when they are less complex.

ChatGPT - Score: 0/5
ChatGPT made up its own “facts” about seasonality for all five companies. Here are a two examples:
Dominos: “The school year can affect Domino's sales. Families with children may order more frequently during the school year when they have less time for cooking.”
According to their disclosure (and confirmed by Bedrock AI), Domino’s business is not seasonal.
Extra Space Storage: "Some individuals may utilize self-storage to store holiday decorations or seasonal items.”
Extra Space Storage’s peak period is May through September, as disclosed by the company (and confirmed by Bedrock AI).
Hila.ai - Score: 0/2*
Hila could not find the answer for two companies (Extra Space Storage, Dominos) and did not have coverage for three companies (Euronet, Flowers Foods, Hamilton Lane).
Unlike ChatGPT, Hila.ai did report that it did not know the answer rather than hallucinate, which is a preferable result.
Bedrock AI - Score: 5/5
Bedrock AI achieved 100% accuracy and recall on this test.
Business segments
While the concept of business or operating segments is not a complex financial topic, we know that it’s one that is not well understood by generalist models. For instance, we have seen GPT-4 conflate the idea of a business segment with user segments, which our finance-specific models understand to be a distinct topic.
We tested whether each tool could correctly identify and retrieve information about a company’s business or operating segments. We tried multiple prompts. The table below summarizes the results.
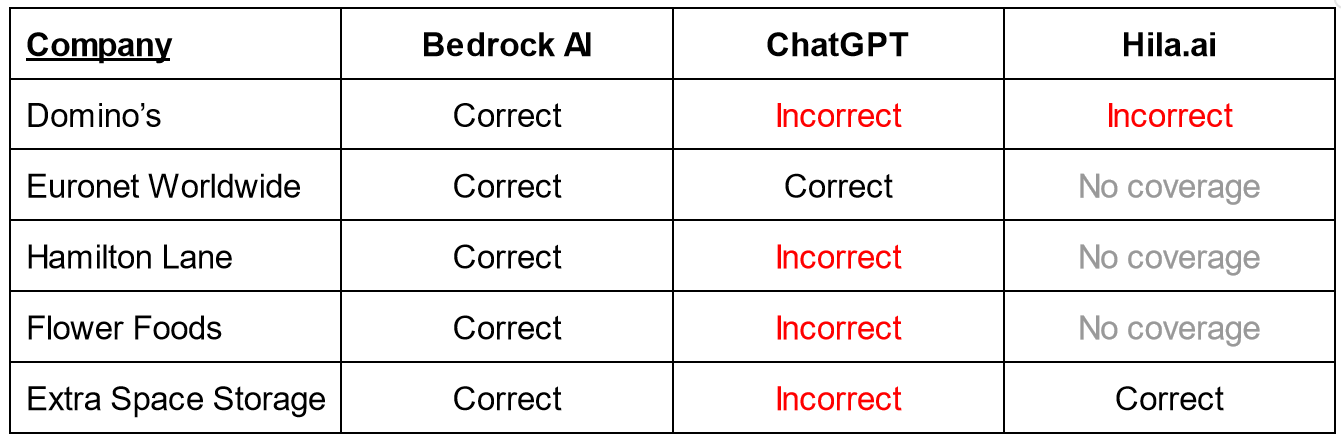
ChatGPT - Score: 1/5
ChatGPT correctly responded for one company out of the five. It correctly answered the business segment prompt for Euronet. Here are the results for the other four companies
Flowers Foods—Like Hamilton Lane, Flower Foods operates a single operating segment, but ChatGPT made up lots of fictional operating segments, and they varied slightly depending on the prompt. In one example, the response stated that the company operated in “Fresh Bakery [...] Specialty and Snacking [...] Frozen Bakery [...] Foodservice and Other.”
All of these segments are completelly invented, and yet, they sound like they shouldould be right.
Hamilton Lane—Like Flowers Foods, Hamilton Lane has a single operating segment, but ChatGPT hallucinated multiple business segments. Different prompt phrasing resulted in different hallucinations.
Extra Space Storage—ChatGPT hallucinated a new segment called “Portable Storage.” The phrase “Portable Storage” never appears in their discosure.
Dominos—The answer varies based on the phrasing of the question. For one version of the prompt, the answer was correct; for the other, it was not.
Hila.ai - Score: 1/2*
Hila did respond correctly for Extra Space Storage. For Dominos, Hila incorrectly states that the information is unavailable in the filing, while in fact it is clearly disclosed. Hila does not yet provide coverage for three companies—Euronet, Flowers Foods, and Hamilton Lane.
Bedrock AI - Score: 5/5
Across all EDGAR issuers, Bedrock AI achieves close to 100% accuracy on business segment identification.
Business operations
We approached this test slightly differently. We asked ChatGPT and Hila.ai specific questions about the details of each company’s operations rather than an open ended one, as done in the above. It’s important to note that in order to get the info you want from a chatbot, this assumes you already know what to ask. We asked for specifics about each company’s business. The following table summarizes whether the tool answered the prompts correctly for each company.

*Provided correct answer but was outdated
** We concluded that Bedrock AI surfaced all relevant, material operational information from the relevant forms related to business operations.The assessment of quality and accuracy was qualitative in this case and therefore subjective.
ChatGPT - Score: 1.5/5
ChatGPT provided a good list of Flowers Foods Inc.’s brands. For Domino’s, it was able to provide the number of locations, but from two years ago, for which we awarded it half a point. ChatGPT could not retrieve material information disclosed in the company’s 10-K for the other three companies.
Hila.ai - Score: 0.5/2
Hila did not have coverage for three companies (Euronet, Flowers Foods, Hamilton Lane). It did retrieve the number of stores for Extra Space Storage but from the company’s previous 10-K filing, not its most recent one. We granted it half a point. For Domino’s, Hila incorrectly reports that information on the number of locations is unavailable in the filing.
Bedrock AI - Score: 5/5
Bedrock AI proactively identifies the most relevant information about a company’s operations, so you do not have to know what to ask.
For instance, here are a few detailed tidbits you will find in Bedrock’s AI-generated background memos, amongst other relevant information about the business operations:
Euronet—“The EFT Processing Segment processes transactions for a network of 45,009 ATMs and approximately 613,000 POS terminals across Europe, Africa, the Middle East, Asia Pacific, and the United States.”
Hamilton Lane—“As of March 31, 2023, the company manages approximately $112 billion of assets under management (AUM) and approximately $745 billion of assets under advisement (AUA).”
Dominos—”Domino's is the largest pizza company globally, operating more than `19,800 locations in over 90 markets.”
The Bedrock AI advantage
As you can see, our results speak for themselves. Most large language models are trained on text from the web. Corporate disclosure, meanwhile, is linguistically and semantically very different, so a general model will struggle to understand the nuance, boilerplate, and legalese effectively.
In a previous post, we outlined the advantages of Bedrock AI’s approach to financial AI and large language models (LLMs).
Here is a summary of our unique advantages:
Domain adaptation—Adapting open source LLMs to securities filings and financial text.
Boilerplate model—Our boilerplate identification model can correctly classify more than 99 percent of sentences as being boilerplate or not. Less boilerplate reduces noise and improves the quality of our input data (and therefore the quality of the output).
Representation learning—For data-oriented applications, the adage is “garbage in, garbage out.” We have extensive processes to ensure we feed high-quality inputs to our models.
Sample-efficient fine-tuning—Our few-shot learning algorithms—models that learn to solve select tasks with a few examples—allow us to extract 328 different types of red flags with just 1,625 labelled sentences.
Text ranking—Not only can our models locate the hard-to-find information, but they can rank it according to relevance and importance.
Training set selection—We use our in-house algorithms for selecting training sets that reduce the chances of shortcut learning. Our algorithms select training examples that give the best value in terms of the number of real-world examples that they could help the model learn to classify correctly.
Want to see Bedrock AI in action? Book a demo